喉頭がんなどの手術で、声帯を摘出し、声を失ってしまったという方は、年間2~3万人と推定されています。そうした人たちが声を取り戻せるかもしれない、そんな技術が色々出てきました。5月13日TBSラジオ「森本毅郎・スタンバイ!」(月~金、6:30~8:30)の「現場にアタック」で、レポーター田中ひとみが取材報告しました。




まずは先月、発表となった新しい技術。開発した株式会社Yellston(エールストン)の早川尚吾さんのお話。
★AI合成音声「コエフォントスタジオ」
- 株式会社Yellston 代表取締役 早川 尚吾さん
- 「「CoeFont STUDIO(コエフォントスタジオ)」という名前で、AIが「打ち込んだ文字」を音声で喋ってくれるサービス。例えば動画を作りたい人は、「声」を自分のキャラクターに吹き込みたい、あるいはナレーターを入れたい時に、声優さんにお願いするのは大変です。従来の機械音声を使う方法もありますが、不自然で、世界観を壊してしまう。でも、この技術を利用すれば、全てディープラーニング(AI)をベースにしているので、より自然な声が出せます。多分、人間か機械かわからないと思います。自分の声を聞くと、「コイツの声、気持ち悪いな」と感じて、「格好良い声で、色々できたら良いな」と思って作りました。」
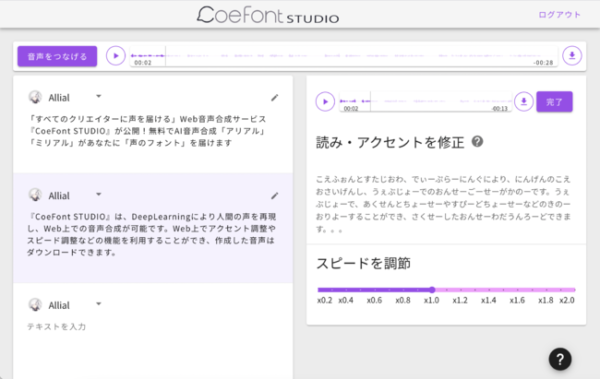
CoeFont STUDIO編集画面(プレスリリースより)
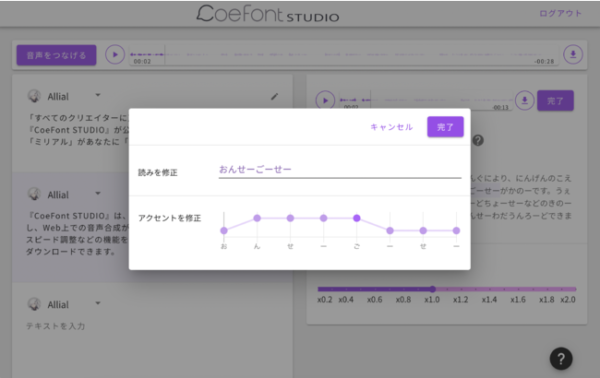
アクセント・ヨミも編集できます(プレスリリースより)
「コエフォントスタジオ」というウェブ上のサービスで、そこで好きな声を選んで、文章を打ち込むと、その通りにしゃべってくれるサービスです。ワープロで文字を書くときにはフォントが選べますが、声もフォントのように選べたら、という発想で作られました。

現状、無料で使える声のフォントその①「アリアル」
もともとは、パソコンやスマホで作った動画などにナレーションを入れたいなと思った時などを想定して作ったそうですが、今後は、病気で声を失う方にも使ってもらいたいという考えもあるようです。
というのも、このサービス、来月からは「誰でも、自分の声を登録できる。それによって、自分の声で、なんでも読ませられる」ようになるということなんです。

エールストンの早川さんに聞きました
でも、そんなに簡単に自分の声のフォントを作れるのか?
★イントネーションが課題
AI田中〈コエフォントで生成した田中キャスターの合成音声〉
- 「声のフォントを作るのは簡単です。まず、こちらの会社で、様々なアクセントがある文章を700ほど、およそ3時間かけて読みます。すると、AIが分析、学習して、声のフォントを完成させます。完成すると、コエフォントのサーバーに登録されて、使えるようになる仕組みです。 」
この部分、放送では、私の声で作った「コエフォント」に読んでもらったのですが、スタジオのみなさん「田中の声だ!」と・・・音声合成された声で、淀みなくスムーズに読んでいました。
これならば、手術で声帯を摘出する前に、自分の声を登録しておけば、手術後も、このウェブサイトを使えば、自分の声で文章が伝えられます。
開発した早川さんは、実は、東京工業大学に通う19歳の現役大学生。今はサービスの利用料を、1文字0円〜数円で調整中です。また、登録した音声は、他の方も利用できます。他の方が利用した場合は、声の持ち主にもお金が入る仕組みとなっています。
★自分の口で喋れる技術「サイリンクス」
さて、失われた声の再現では、今のサービスのように「書いた文字を機械に読ませる」のではなく、「自分の口でしゃべれるように」という開発も進められています。こちらも同じく、現役学生。東京大学・大学院生のグループ「サイリンクス」のリーダー、竹内雅樹さん。
- 「サイリンクス」リーダー 竹内雅樹さん
- 「失われた声を取り戻すデバイス「サイリンクス」。形は、首輪のようになっていて、首に巻いて、口の形を動かすと、それに連動して口から音が出ます。そもそも人の声を出す原理は、肺からの空気を、「声帯」という筋肉が、開いたり閉じたりを素早く繰り返すことで、「ブー」という、空気を振動音に変えています。それを、口や舌の形によって、音の違いを作るというわけです。だから、声帯を失った人は、声帯が作り出す音が作れないので、外部から声の元となる振動を与えてあげれば、声を口から出す事ができます。」

音声発生装置「サイリンクス」。首元にある丸い物体が、小刻みに振動し、声帯の「震え」の代わりを務めます。この状態で、喋りたい言葉を口パクすると、口から「声」が産生します
私たちは、声帯を震わせて声を出しており、喉のがん(喉頭癌や咽頭癌)で声帯を摘出してしまうと、声の元となるバイブレーションが失われてしまいます。
そこで、この首輪型の機器を「疑似声帯」として、首に巻いて使用。喋りたい時は、スイッチを入れて喉元を震わせれば、喋りたい形に口を動かすだけで、口から音が出ます。
現在、同様の機械はありますが、手で強く押し当てる必要があり不自然。周りの目も気になる。こちらはハンズフリーで自然・・そこを目指したかったそうです。
実演してもらいましたが、たしかにご本人の口から、声が出ていました。
★口パクでしゃべれる!
- 竹内さん〈サイリンクス使用〉
- 「こんにちは、竹内です。よろしくお願いします。 」
- 田中
- 「お昼ご飯は食べましたか? 」
- 竹内さん〈サイリンクス使用〉
- 「後で食べます!」
口パクで声が出ていました!声を失ってしまった方でもしゃべれるというのは、とてもすごいことだなと感じました。
一方で、まだ開発段階なので仕方ないのですが、この方法では、言葉に抑揚がなく、イントネーションが平板なのが気になります。これは仕方のないことなのでしょうか?
- 竹内さん
- 「ご指摘の所が人の声から遠い部分。この振動音は常に平板の音を与えているだけなので、それを使ってしゃべってもアクセントが与えられないんです。ここは、今の技術では難しいですが、卒業するまでの3年以内に、ある程度の範囲の方の声を実現したいと思っています。当たり前のように出していた声を失うと、孤独感や、不便な生活を強いられます。だから、自分の声で話すことができる社会を実現したい。」

「サイリンクス」のリーダー、竹内 雅樹さんに聞きました
今は元となる振動音が平板なので、平板な喋り方しかできません。でも、この振動音にアクセントやイントネーションを作れれば、もっと自然に喋れるようになるようで、その仕組みなどは、研究論文も出てきているということで、今後取り組むということでした。
「自分の体、自分の口で喋る」という、本当の意味で声を取りところにこだわり、今後も開発を続けるそうです。